AI Systems Are Not Failing Where You Think
AI systems are not breaking because models are weak. They are breaking because no one is designing how they behave under attack at runtime.
We are still securing AI systems like traditional software:
- Static logic
- Predictable execution
- Clearly defined boundaries
AI systems are none of these. They generate behavior dynamically, based on:
- Untrusted input
- Retrieved data
- External tools
- Runtime decisions
You are no longer securing code. You are securing behavior.
The Real Failure Point: Inference
Most teams focus on:
- Model quality
- Prompt design
- Retrieval accuracy
But failures don’t originate there. They emerge during inference, when the system is live,
- User input influences behavior
- Internal data is injected into context (RAG)
- Models generate decisions
- Tools are executed
- Outputs are returned
This is where AI systems are actually attacked.
The Missing Layer: Inference Engineering
Inference engineering is the discipline of designing how AI systems behave at runtime. It is responsible for controlling:
- Input handling
- Context injection
- Model interaction patterns
- Tool execution
- Output enforcement
This is not model tuning. This is system design under adversarial conditions.
The Other Missing Layer: Speculative Engineering
Even well-designed systems fail over time. Not because they are poorly built but because they evolve.
Speculative engineering addresses this: It designs systems based on how they are likely to fail in the future, not just how they behave today.
It forces you to ask:
- What happens when this system scales?
- What happens when agents become autonomous?
- What happens when attackers automate interaction?
Why You Need Both
Inference engineering without speculation:
→ Handles current failures
→ Breaks under new attack patterns
Speculative engineering without inference awareness:
→ Stays theoretical
→ Misses real attack surfaces
Together: You design systems that are resilient under both present and future adversarial conditions.
The Inference Pipeline Is a Distributed System
Treat it like one.
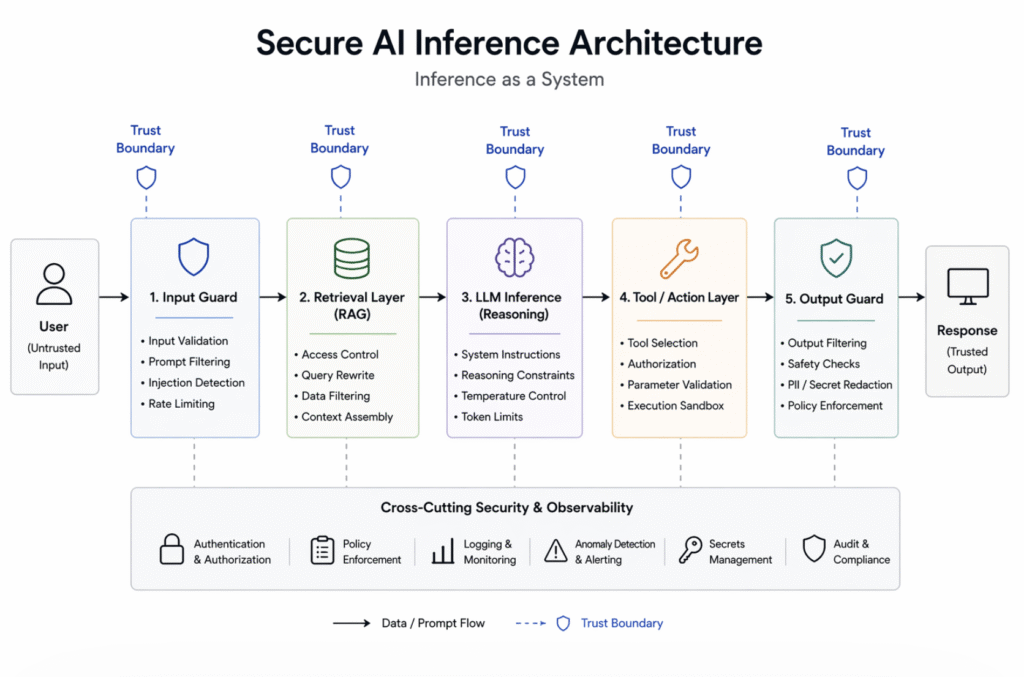
Figure: A simplified secure AI inference architecture showing runtime trust boundaries, control layers, and where security must be enforced.
Every stage is a trust boundary. Every boundary is a potential attack surface.
Where Systems Break (Today → Tomorrow)
1. Prompt Injection → Behavior Hijacking
Today: User input overrides system intent
Tomorrow: Multi-step agent manipulation across systems
Design response:
- Instruction hierarchy
- Input isolation
- Context segmentation
2. RAG → Data Exfiltration
Today: Sensitive documents leak through retrieval
Tomorrow: Targeted extraction across knowledge systems
Design response:
- Retrieval access control
- Context boundary enforcement
- Data-aware filtering
3. Tool Execution → Language-to-Action Exploits
Today: Unsafe API calls and parameter abuse
Tomorrow: Autonomous attack chains orchestrated by AI
Design response:
- Tool authorization
- Parameter validation
- Execution sandboxing
4. Output Layer → Silent Leakage
Today: Hallucinations and unsafe responses
Tomorrow: Covert data exfiltration through outputs
Design response:
- Output filtering
- Response validation
- Policy enforcement
The Core Principle:
Every inference pipeline operates under adversarial input conditions.
If you wouldn’t trust it in a distributed system, you shouldn’t trust it in an AI system.
A Practical Way to Think About It
Instead of asking: “Does this model work?”
Ask:
- “What happens when this inference flow is manipulated?”
- “Where does implicit trust exist?”
- “How does failure propagate across components?”
Design at the Right Layer
Most teams try to fix problems inside the model. That’s the wrong place.
The control points are in the system:
- Identity-aware retrieval
- Context isolation
- Tool execution guardrails
- Output enforcement
The model generates behavior.
The system must constrain it.
Reality Check
No system is fully secure. There will always be:
- Unknown attack patterns
- Model unpredictability
- Human misuse
The goal is not perfection.
The goal is: Preventing small failures from becoming systemic breaches.
The Shift That Matters
We are no longer building static software. We are building systems that:
- Generate decisions
- Interact with other systems
- Act on behalf of users
This is runtime decision infrastructure. And it must be designed accordingly.
Final Thought
Speculative engineering asks: How will this system fail tomorrow?
Inference engineering asks: How is this system failing right now under real input?
The engineers who understand both: Will define how secure AI systems are actually built.
Closing Position
This is the shift:
- From securing code → to securing behavior
- From fixing vulnerabilities → to designing failure-resistant systems
That’s where AI security is moving. And that’s where it needs to be designed, not patched.
Leave a Reply